Р4Р тренировки – 8 4 — 1 » —
5 тренировочных программ лучших боксеров р4р — Fitness Сейчас

5 ТРЕНИРОВОЧНЫХ ПРОГРАММ ЛУЧШИХ БОКСЕРОВ Р4Р
МУХАММЕД АЛИ
Тренировки Али были нацелены на отработку именно тех навыков, которые помогали ему достигать победы. Он много работал со скакалкой, прыгал, отрабатывал «бой с тенью», работал на скоростной груше. Примечательны тренировки тем, что Мухаммед Али практически не работал с отягощенными. Особое внимание обращал на режим питания. Ел только натуральную пищу.
Каждое утро, не зависимо от погоды, Мохаммед Али начинал с того, что подымался в утра и пробегал 6 миль (около 11 км) в армейских ботинках. Затем он продолжал спать. Потом завтрак, и приходил в зал к 12:30.
В зале у Мухаммеда Али была в основном однообразная программа тренировок:
Разминка — растяжка корпуса, ног и т.п. — около 15 минут
Бой с тенью — 12 ранудов по 3 минуты с перерывами в 30 секунд
Работа на мешке — 6 раундов по 3 минуты с перерывами по 30 секунд
Спарринги — не менее 5 раундов по 3 минуты в зависимости от этапа подготовки к бою
Гимнастика — упражнения на полу: подкачка пресса — около 15 минут
Работа на пневмогруше — 9 минут
Бой с тенью — 1 минута
Скакалки — 20 минут
Флойд Мейвезер:
Бойцовские тренировки Мэйуэзера проходят немного иначе, чем у большинства боксёров. Он проводит короткую разминку, потом надевает перчатки и направляется в ринг. В ринге его ждут 4 партнера, с каждым из которых он работает по 10 минут. Смена свежих партнеров заставляет его организм все 4 боя работать на максимуме, что положительно сказывается как на выносливости тая к и на скоростно-силовых качествах.
Со скоростным мешком Мэйуэзер работает по 5 и 15 минут на максимальной скорости. В течении 7 минут он наносит около 800 ударов. После скоростной работы с
На тяжелом мешке мешке он проводит 30-40 минут отрабатывая скорость и силу удара.
Кроме стандартных упражнений Мэйуэзер играет в баскетбол, проводит тренировки с закрытыми глазами, бросает вверх по 2000 ударов.
Часто тренировки Мэйуэзера начинаются очень рано, бывает и в 3 часа утра.
Его тренировка включает:
Спарринг (40 минут)
Работа на скоростной груше (5-15 минут)
Работа на мешках (30-40 минут)
Пробежка (5-8 км)
По 200 приседаний, подтягиваний, отжиманий
Скакалка (15 минут)
Бой с тенью (5 минут)
Упражнения на пресс, подъемы
Майк Тайсон:
Основа тренировки Майка Тайсона — это его распорядок дня. Чтобы достичь таких же успехов, вам нужно будет стремиться к тому, чтобы в точности повторять этот распорядок.
Как уже было сказано ранее, тренировки Майка Тайсона — это не просто набор упражнений, это полноценный образ жизни, поэтому заниматься по его программе стоит только тем, кто рассчитывает на спортивную карьеру или имеет очень много свободного времени, ведь у Майка весь день превращался в одну большую тренировку.
Режим дня (Будни – «рабочие дни», суббота и воскресенье – выходные):
5 часов утра
6 часов утра: душ и дальнейший сон
10 часов утра: подъем, завтрак (Майк предпочитает стейк с макаронами и апельсиновый сок)
12 часов дня: 10 раундов спарринга на ринге
2 часа дня: обед (к слову, обедает Майк точно то же, что и завтракает. Как и ужинает – Тайсон не особый гурман)
4 часа дня:
Работа на ринге (включая работу с грушами, тяжелая груша в последнюю очередь)
Бой с тенью
Велотренажер
5 часов вечера:
2000 подъемов туловища из положения леж,
50-80 отжиманий на брусьях, 50 отжиманий от пола,
500 повторений — шраги с 30 кг, и после этого 10 минут на шею.
Упражнения для шеи делятся на 10 подходов — соответственно 200 подъемов
25-40 на брусьях, 50 отжиманий, 50 — шраги, и далее по новой.
Рой Джонс:
Звезда мирового бокса — Рой Джонс младший — это не просто боксер. Это Человек, благодаря которому бокс вернул себе зрелищность. Человек, вложивший в бокс всю свою жизнь — это символ, наряду с Мухаммедом Али и Майком Тайсоном. Тренировки Джонса сделали его таким какой он есть — быстрым, сильным, резким и неуловимым. Он был Чемпионом Мира в нескольких весовых категориях и именно поэтому можно ставить тренировки этого боксера в пример всем.
Рой Джонс, несмотря на свой огромный природный талант был очень и очень трудолибив и трудоспособен. Мало кто выдерживал такой темп тренировки, как он, в течение длительного периода времени.
График тренировок боксера выглядел следующим образом:
Шесть дней в неделю Рой поднимался около 5:30 утра, делал растяжку мышц и пробегал примерно 5-8 км,
Затем шел спать.
Тренировка дневная начиналась около 12 часов дня и длилась 2,5 — 3 часа.
За это время Рой успевал:
Разминка
Бой с тенью 4 раунда по четыре минуты (между раундами перерыв 30 секунд)
Работа на скоростной груше 16 минут (по завершении упражнения перерыв 30 секунд)
Работа с грушей на растяжках между полом и потолком 16 минут (по завершении упражнения перерыв 30 секунд)
Скакалка 25 минут с постоянной скоростью (перерыв 1 минута)
Работа на мышцы пресса:
4 подхода по 100 подъемов туловища из положения лежа (после каждого подхода перерыв 30 секунд)
4 подхода по 100 подъемов ног (после каждого подхода перерыв 30 секунд)
4 подхода по 100 складок
fitness-now.ru
TRX-петли (ремень для фитнеса) Suspension Training Р1
ОДИН ТРЕНАЖЕР — БЕЗГРАНИЧНЫЕ ВОЗМОЖНОСТИ!

TRX петли Suspension Training – это функциональные подвесные устройства, которые активно используются при силовых тренировках и во время обычной разминки. Их главная особенность в том, что за счет работы с собственным весом позволяют не только сжигать лишние калории, но и укреплять мышцы, делать их рельефными, здоровыми. Изготавливаются петли TRX из сверхпрочных, но легких нейлоновых лямок с мягкими ручками, что обеспечивает высокий комфорт спортсмена во время тренировки и делает каждое занятие максимально приятным и эффективным.
Комплект включает в себя все, что вам нужно для увеличения силы, выносливости, гибкости и мобильности:
- петли TRX со страховочной петлей — 2 шт.
- карабин
- прорезиненные ручки
- крепление на дверь Door Anchor
- удлинитель TRX Xtender
- фирменная сумка TRX
- браслет TRX
- табличка на дверь
- DVD с базовыми упражнениями
- руководство по использованию
* Комплектация может несколько отличаться от заявленной. Уточняйте у менеджеров!
Тренажер, который подходит для всех и каждого
Петли являются универсальным устройством для любого человека, чья деятельность или увлечения связаны со спортом:
Йога |
Фитнес |
Бег |
Профессиональный спорт |
Любительский сорт |
Воинская служба |





В каждом случае тренажер становится эффективным инструментом, позволяющим развивать спортивные навыки и оттачивать свое мастерство по работе с собственным весом.
Тренажер отличается своей универсальностью и портативностью
TRX петли отличаются от других тренажеров рядом преимуществ, которые делают их максимально привлекательными для спортсменов любого уровня подготовки и телосложения:
Функциональность На одном устройстве вы можете тренировать практически все мышцы своего тела | Универсальность Петли можно использовать в любых тренировочных программах и со спортсменами любого уровня подготовки | Компактность Тренажер легкий по весу и маленький по габаритам, поэтому проводить тренировки вы сможете в удобном для вас месте. |
Вам доступно более 300 упражнений на одном устройстве!
Не верите? Посмотрите видео об упражнениях с TRX-петлями, и вы лично убедитесь в универсальности и эффективности тренажера:
wildsportprof.ru
Глубокое обучение на R, тренируем word2vec / Habr
Word2vec является практически единственным алгоритмом deep learning, который сравнительно легко можно запустить на обычном ПК (а не на видеокартах) и который строит распределенное представление слов за приемлемое время, по крайней мере так считают на Kaggle. Прочитав здесь про то, какие фокусы можно делать с тренированной моделью, я понял, что такую штуку просто обязан попробовать. Проблема только одна, я преимущественно работаю на языке R, а вот официальную реализацию word2vec под R мне найти не удалось, думаю её просто нет.Зато есть исходники word2vec на C и описание на сайте Google, а в R есть возможность использовать внешние библиотеки на C, C++ и Fortran. Кстати, самые быстрые библиотеки R сделаны именно на C и С++. Еще есть R-обертка tmcn.word2vec, которая находится в стадии разработки. Её автор,
Jian Li (сайт на китайском) сделал что-то вроде демоверсии для китайского языка (с английским тоже работает, с русским пока не пробовал). Проблемы с этой версией следующие:
- Во-первых, все параметры зашиты в C-коде;
- Во-вторых, автор сделал только одну функцию для работы с обученной моделью – distance, которая оценивает сходство слов и выводит 20 вариантов с максимальным значением;
- В-третьих, мне не удалось собрать пакет под x64 Windows. На win32 пакет ставится без проблем.
Оценив всё это «богатство», я решил сделать свой вариант R-интерфейса к word2vec. Сказать по правде, не очень хорошо знаю С, приходилось писать только простенькие программы, поэтому за основу я решил взять исходники Jian Li, потому что они точно компилируются под Windows, иначе бы не было пакета. Если что-то не будет работать, их всегда можно сверить с оригиналом.
Подготовка
Для того чтобы компилировать C-код для R под Windows нужно дополнительно установить Rtools. Этот набор инструментов содержит компилятор gcс, который запускается под Cygwin. После установки Rtools нужно проверить переменную PATH. Там должно быть что-то вроде:
D:\Rtools\bin;D:\Rtools\gcc-4.6.3\bin;D:\R\bin
Под OS X никаких Rtools не требуется. Нужен установленный компилятор, наличие которого проверяется командой gcc —version. Если его нет, нужно установить Xcode и через Xcode — Command Line Tools.
Про вызов С-библиотек из R нужно знать следующее:
- Все значения при вызове функции передаются в виде указателей и нужно позаботиться о том, чтобы в явном виде прописать их тип. Надежнее всего работает передача параметров типа char с последующим преобразованием в нужный тип уже в C;
- Вызываемая функция не возвращает значение, т.е. должна быть типа void;
- В C-код нужно добавить инструкцию #include <R.h>, а если есть сложная математика, то еще и #include <R.math>;
- Если нужно что-то вывести на консоль R, вместо printf() лучше использовать Rprintf(). Правда у меня printf() тоже работает.
Для начала я решил сделать что-то очень простое, типа Hello, World! Но так, чтобы туда передавалось какое-либо значение. Rstudio, которой я обычно пользуюсь, позволяет писать C и C++ код и всё правильно подсвечивает. Написав и сохранив код в hello.c я вызвал командную строку, перешел в нужный каталог и запустил компилятор следующей командой:
> R --arch x64 CMD SHLIB hello.c
Под win32 ключ архитектуры не нужен:
> R CMD SHLIB hello.c
В результате, в каталоге появилось два файла, hello.o (его можно смело удалить) и библиотека hello.dll. (На OS X вместо dll получится файл с расширением so). Вызов полученной функции hello в R осуществляется следующим кодом:
dyn.load("hello.dll")
hellof <- function(n) {
.C("hello", as.integer(n))
}
hellof(5)
Тест показал, что всё работает правильно и для экспериментов с word2vec осталось подготовить данные. Я решил взять их на Kaggle из задачи «Bag of Words Meets Bags of Popcorn». Там есть обучающая, тестовая и неразмеченная выборки, которые в сумме содержат сто тысяч ревю фильмов из IMDB. Загрузив эти файлы, я убрал из них HTML-теги, специальные символы, цифры, знаки препинания, стоп-слова и токенизировал. Подробности обработки опускаю, я про них уже писал.
Word2vec принимает данные для обучения в виде текстового файла с одной длинной строкой, содержащей слова, разделенные пробелами (выяснил это, анализируя примеры работы с word2vec из официальной документации). Склеил наборы данных в одну строку и сохранил её в текстовом файле.
Модель
В варианте Jian Li — это два файла word2vec.h и word2vec.c. В первом содержится основной код, который в главном совпадает с оригинальным word2vec.c. Во втором — обертка для вызова функции TrainModel(). Первое, что я решил сделать — вытащить все параметры модели в R-код. Нужно было отредактировать R-скрипт и обертку в word2vec.c, получилась вот такая конструкция:
dyn.load("word2vec.dll")
word2vec <- function(train_file, output_file,
binary,
cbow,
num_threads,
num_features,
window,
min_count,
sample)
{
//...здесь вспомогательный код и проверки...
OUT <- .C("CWrapper_word2vec",
train_file = as.character(train_file),
output_file = as.character(output_file),
binary = as.character(binary), //... аналогично другие параметры
)
//...здесь вывод диагностики из выходного потока OUT...
}
word2vec("train_data.txt", "model.bin",
binary=1, # output format, 1-binary, 0-txt
cbow=0, # skip-gram (0) or continuous bag of words (1)
num_threads = 1, # num of workers
num_features = 300, # word vector dimensionality
window = 10, # context / window size
min_count = 40, # minimum word count
sample = 1e-3 # downsampling of frequent words
)
Несколько слов про параметры:
binary — выходной формат модели;
cbow — какой алгоритм использовать для обучения skip-gram или мешок слов (cbow). Skip-gram работает медленнее, но дает лучший результат на редких словах;
num_threads — количество потоков процессора, задействованных при построении модели;
num_features — размерность пространства слов (или вектора для каждого слова), рекомендуется от десятков до сотен;
window — как много слов из контекста обучающий алгоритм должен принимать во внимание;
min_count — ограничивает размер словаря для значимых слов. Слова, которые не встречаются в тексте больше указанного количества, игнорируются. Рекомендованное значение — от десяти до ста;
sample — нижняя граница частоты встречаемости слов в тексте, рекомендуется от .00001 до .01.
Компилировал следующей командой с рекомендованными в makefile ключами:
>R --arch x64 CMD SHLIB -lm -pthread -O3 -march=native -Wall -funroll-loops -Wno-unused-result word2vec.c
Компилятор выдал некоторое количество предупреждений, но ничего серьезного, заветная word2vec.dll появилась в рабочем каталоге. Без проблем загрузил её в R функцией dyn.load(«word2vec.dll») и запустил одноименную функцию. Думаю, полезным является только ключ pthread. Без остальных можно обойтись (часть из них прописана в конфигурации Rtools).
Результат:
Всего в моем файле оказалось 11.5 млн. слов, словарь — 19133 слова, время построения модели 6 минут на компьютере с Intel Core i7. Чтобы проверить, работают ли мои параметры, я поменял значение num_threads с единицы на шесть. Можно было бы и не смотреть на мониторинг ресурсов, время построения модели сократилось до полутора минут. То есть эта штука умеет обрабатывать одиннадцать миллионов слов за минуты.
Оценка сходства
В distance я практически ничего менять не стал, только вытащил параметр количества возвращаемых значений. Затем скомпилировал библиотеку, загрузил её в R и проверил на двух словах «bad» и «good», учитывая, что имею дело с положительными и отрицательными ревю:
Word: bad Position in vocabulary: 15
Word CosDist
1 terrible 0.5778409
2 horrible 0.5541780
3 lousy 0.5527389
4 awful 0.5206609
5 laughably 0.4910716
6 atrocious 0.4841466
7 horrid 0.4808238
8 good 0.4805901
9 worse 0.4726501
10 horrendous 0.4579800
Word: good Position in vocabulary: 6
Word CosDist
1 decent 0.5678578
2 nice 0.5364762
3 great 0.5197815
4 bad 0.4805902
5 excellent 0.4554003
6 ok 0.4365533
7 alright 0.4361723
8 really 0.4153538
9 liked 0.4061105
10 fine 0.4004776
Всё снова получилось. Интересно, что от bad до good дистанция больше чем от good до bad если считать в словах. Ну, как говорится «от любви до ненависти…» ближе чем наоборот. Алгоритм рассчитывает сходство как косинус угла между векторами по следующей формуле (картинка из вики):
А значит, имея обученную модель, можно рассчитать дистанцию без С, и вместо сходства оценить, например, различия. Для этого нужно построить модель в текстовом формате (binary=0), загрузить её в R при помощи read.table() и написать некоторое количество кода, что я и сделал. Код без обработки исключений:
similarity <- function(word1, word2, model) {
size <- ncol(model)-1
vec1 <- model[model$word==word1,2:size]
vec2 <- model[model$word==word2,2:size]
sim <- sum(vec1 * vec2)
sim <- sim/(sqrt(sum(vec1^2))*sqrt(sum(vec2^2)))
return(sim)
}
difference <- function(string, model) {
words <- tokenize(string)
num_words <- length(words)
diff_mx <- matrix(rep(0,num_words^2), nrow=num_words, ncol=num_words)
for (i in 1:num_words) {
for (j in 1:num_words) {
sim <- similarity(words[i],words[j],model)
if(i!=j) {
diff_mx[i,j]=sim
}
}
}
return(words[which.min(rowSums(diff_mx))])
}
Здесь строится квадратная матрица размером количество слов в запросе на количество слов. Дальше для каждой пары несовпадающих слов рассчитывается сходство. Потом значения суммируются по строкам, находится строка с минимальной суммой. Номер строки соответствует позиции «лишнего» слова в запросе. Работу можно ускорить, если считать только половину матрицы. Пара примеров:
> difference("squirrel deer human dog cat", model)
[1] "human"
> difference("bad red good nice awful", model)
[1] "red"
Аналогии
Поиск аналогий позволяет решать задачки типа «мужчина относится к женщина как король относится к ?». Специальная функция word-analogy есть только в оригинальном коде Google, поэтому с ней пришлось повозиться. Я написал обертку для вызова функции из R, убрал из кода бесконечный цикл и заменил стандартные потоки ввода-вывода на передачу параметров. Затем скомпилировал в библиотеку и сделал несколько экспериментов. Штука с королем-королевой у меня не получилась, видимо одиннадцати миллионов слов маловато (авторы word2vec рекомендуют в районе миллиарда). Несколько удачных примеров:
> analogy("model300.bin", "man woman king", 3)
Word CosDist
1 throne 0.4466286
2 lear 0.4268206
3 princess 0.4251665
> analogy("model300.bin", "man woman husband", 3)
Word CosDist
1 wife 0.6323696
2 unfaithful 0.5626401
3 married 0.5268299
> analogy("model300.bin", "man woman boy", 3)
Word CosDist
1 girl 0.6313665
2 mother 0.4309490
3 teenage 0.4272232
Кластеризация
Почитав документацию я понял, что оказывается в word2vec есть встроенная K-Means кластеризация. И чтобы ей воспользоваться достаточно «вытащить» в R еще один параметр — classes. Это количество кластеров, если оно больше нуля, word2vec выдаст текстовый файл формата слово — номер кластера. Триста кластеров оказалось мало чтобы получить что-то вменяемое. Эвристика от разработчиков: размер словаря поделенный на 5. Соответственно выбрал 3000. Приведу несколько удачных кластеров (удачных в том смысле, что я понимаю, почему эти слова рядом):
word id
335 humor 2952
489 serious 2952
872 clever 2952
1035 humour 2952
1796 references 2952
1916 satire 2952
2061 slapstick 2952
2367 quirky 2952
2810 crude 2952
2953 irony 2952
3125 outrageous 2952
3296 farce 2952
3594 broad 2952
4870 silliness 2952
4979 edgy 2952
word id
1025 cat 241
3242 mouse 241
11189 minnie 241
word id
1089 army 322
1127 military 322
1556 mission 322
1558 soldier 322
3254 navy 322
3323 combat 322
3902 command 322
3975 unit 322
4270 colonel 322
4277 commander 322
7821 platoon 322
7853 marines 322
8691 naval 322
9762 pow 322
10391 gi 322
12452 corps 322
15839 infantry 322
16697 diver 322
С помощью кластеризации нетрудно сделать сентимент-анализ. Для этого нужно построить «мешок кластеров» — матрицу размером количество ревю на максимальное количество кластеров. В каждой ячейки такой матрицы должно быть количество попаданий слов из ревю в заданный кластер. Я не пробовал, но проблем здесь не вижу. Говорят, что точность для ревю из IMDB получается такой же или немного меньше, чем если это делать через «Мешок слов».
Фразы
Word2vec умеет работать с фразами, вернее с устойчивыми сочетаниями слов. Для этого в оригинальном коде есть процедура word2phrase. Её задача – найти часто встречающиеся сочетания слов и заменить пробел между ними на нижнее подчеркивание. Файл, который получается после первого прохода содержит двойки слов. Если его снова отправить в word2phrase, появятся тройки и четверки. Результат потом можно использовать для тренировки word2vec.
Сделал вызов этой процедуры из R по аналогии с word2vec:
word2phrase("train_data.txt",
"train_phrase.txt",
min_count=5,
threshold=100)
Параметр min_count позволяет не рассматривать словосочетания, встречающиеся мене заданного значения, threshold управляет чувствительностью алгоритма, чем больше значение, тем меньше фраз будет найдено. После второго прохода у меня получилось около шести тысяч сочетаний. Чтобы посмотреть на сами фразы я сначала сделал модель в текстовом формате, вытащил оттуда столбец слов и отфильтровал по нижнему подчеркиванию. Вот фрагмент для примера:
[5887] "works_perfectly" "four_year_old" "multi_million_dollar" [5890] "fresh_faced" "return_living_dead" "seemed_forced" [5893] "freddie_prinze_jr" "re_lucky" "puerto_rico" [5896] "every_sentence" "living_hell" "went_straight" [5899] "supporting_cast_including" "action_set_pieces" "space_shuttle"
Выбрал несколько фраз для distance():
> distance("p_model300_2.bin", "crouching_tiger_hidden_dragon", 10)
Word: crouching_tiger_hidden_dragon Position in vocabulary: 15492
Word CosDist
1 tsui_hark 0.6041993
2 ang_lee 0.5996884
3 martial_arts_films 0.5541546
4 kung_fu_hustle 0.5381692
5 blockbusters 0.5305687
6 kill_bill 0.5279162
7 grindhouse 0.5242150
8 churned 0.5224440
9 budgets 0.5141657
10 john_woo 0.5046486
> distance("p_model300_2.bin", "academy_award_winning", 10)
Word: academy_award_winning Position in vocabulary: 15780
Word CosDist
1 nominations 0.4570983
2 ever_produced 0.4558123
3 francis_ford_coppola 0.4547777
4 producer_director 0.4545878
5 set_standard 0.4512480
6 participation 0.4503479
7 won_academy_award 0.4477891
8 michael_mann 0.4464636
9 huge_budget 0.4424854
10 directorial_debut 0.4406852
На этом я эксперименты пока завершил. Одно важное замечание, word2vec «общается» с памятью напрямую, в результате R может работать нестабильно и аварийно завершать сессию. Иногда это связано с выводом диагностических сообщений от ОС, которые R не может корректно обработать. Если ошибок в коде нет, то помогает перезапустить интерпретатор или Rstudio.
R-код, исходники на C и скомпилированные под x64 Windows dll в моем репозитарии.
UPD:
В результате спора с ServPonomarev и последующего анализа кода word2vec, удалось выяснить, что алгоритм обучается строками по 1000 слов, по которым движется окно в плюс/минус 5 слов. При обнаружении символа EOL, который алгоритм преобразует в специальное слово с нулевым номеров в словаре, движение окна останавливается и продолжается уже в новой строке. Представление слов, разделенных EOL, в модели будет отличаться от представления этих же слов, разделенных пробелом. Вывод: если исходный текст — это совокупность документов, а также фраз или абзацев, разделенных переводом строки, не стоит избавляться от этой дополнительной информации, т.е. оставить символы EOL в обучающей выборке. К сожалению, проиллюстрировать это примерами весьма сложно.
habr.com
7 приемов эффективной тренировки — R-dance
Традиции в тренировочном процессе – это хорошо, но существует множество современных технологий, позволяющих сделать обучающий процесс ярким и творческим. Нетрадиционный подход способствует повышению результативности тренировок. В первую очередь возможные изменения касаются формы проведения занятий.
Классический тренировочный урок, описанный в книгах по бальным танцам, имеет определенную структуру:
- разминка;
- растяжка связок и мышц;
- разогрев;
- основная часть тренировки с максимальной нагрузкой;
- заключительная растяжка.
Нетрадиционные приемы эффективной тренировки
1. Внести разнообразие можно путем изменения положения учеников на танцевальной площадке (диагонально к центру, спиной к зеркальной стене, на ограниченном заданными ориентирами пространстве) или изменение направлений движения. Такая практика тренирует пространственную ориентировку, совершенствует межполушарное взаимодействие, развивает способность подстраиваться под меняющиеся окружающие условия.
2. Наблюдение – важное умение для танцора. Полезно периодически делить группу на “исполнителей”, которые демонстрируют композицию и “зрителей”, которые ведут наблюдение и анализ деятельность “исполнителей”. Такой опыт помогает оценить сильные и слабые стороны товарищей. К тому же чужие ошибки со стороны видны отчетливее. Заметив их, танцоры-зрители стараются не допустить подобные недостатки в своем выступлении.
3. Изучение нового элемента начинается с показа тренера. Важно понять не только рисунок движения, но и эмоциональную составляющую. Целостное восприятие позволяет постигнуть драматургию, танцевальный замысел в полной мере.
4. Хореографическая память – это важно, но использование современных технических средств имеет свое преимущество. Запись исполнения на видео – это замечательная возможность наблюдать за собственным танцеванием, анализируя свои ошибки.
5. Используя на занятиях специфические звуки, эффекты освещения, можно существенным образом дополнить занятие творческой фантазией, обогатить выразительностью тот или иной художественный образ. Такой опыт способствует развитию артистизма танцевальной пары.
6. Возможность импровизации и перевоплощения очень значима для роста профессионального мастерства, выработки собственного стиля. Такой прием помогает лучше услышать и почувствовать музыку. К тому же в процессе импровизации могут появиться новые идеи для танцевальной композиции.
7. Важным моментом является конструктивный диалог между участниками тренировки. Побуждать к размышлениям, возражениям, постановкам вопросов необходимо, как условие сознательного восприятие материала. Живое общение помогает налаживать личностные отношения, тем самым чутко регулирует процесс обучения. Иногда признание тренером своих недочетов в программе тренировки способствует более настойчивой отработке танцорами сложных фигур. Ребенок хочет танцевать тогда, когда с его жизненной позицией считаются окружающие и его мнение востребовано.
Хореографическая дидактика и приемы эффективной тренировки дадут положительный результат при условии создания комфортной и творческой танцевальной атмосферы. Это обеспечит богатый опыт не только ученикам, но и педагогам.
r-dance.club
Как произносить английский звук r: пошаговое руководство
Судя по видеогидам, которые учат изображать “русский акцент”, его звучание, в основном, определяют звуки th, пара d-t, несколько гласных и – звук |r|. Именно он делает акцент настолько узнаваемым, и это даже обыгрывается в пародиях:
На самом деле, научиться произносить звук |r| не так сложно. Главное приучить себя правильно артикулировать звук в беглой речи. Выход один – много практики. Так что наш план действий: сначала пошагово разберем, как правильно произнести звук |r|, а после – попрактикуемся на словах и скороговорках.
Пошаговое руководство: как произносить английский звук |r|
1 шаг. Мы уже учились произносить пару согласных |d-t|. Для этого ставили кончик языка на альвеолы (бугорки за зубами). Нащупай их прямо сейчас и скажи слово day |deɪ|.

Для произнесения звука |r| нужно переместить кончик языка ЗА эту точку, то есть на задний скат альвеол. Найди его языком (я подожду).
2 шаг. НО! Касаться кончиком языка этой заальвеолярной точки не нужно. Кончик языка находится возле нее, на некотором расстоянии. Между задним скатом альвеол и кончиком языка остается щель, через которую пойдет воздух. Готово? Идем дальше.
3 шаг. Следующий важный момент: язык должен быть напряжен. Обрати внимание: когда ты произносишь русский звук |p|, язык занимает примерно такое же положение, но он расслаблен. Поэтому язык дрожит (вибрирует) от потока воздуха, как тростинка на ветр(рррррррр)у, и ударяется о небо и корни зубов.
Тогда как для английского “аналога” язык – стойкий оловянный солдатик, поэтому воздух спокойно проходит через приготовленную для него щель, и вибрации в звуке нет. Звук получается ненапряженный. Вибрируют только голосовые связки.
Итак, теперь на раз-два-три: ставим кончик языка к заднему скату альвеол, но оставляем щель между ними, держим язык напряженным и произносим слово rat /ræt/. Получилось? 🙂
Видеоинструкция: произношение английского |r|
Для закрепления результата посмотрим подробную видеоинструкцию. Она англоязычная, но ты разберешься, ведь мы только что проговорили все детали.
Видео: r sound pronunciation. Еще одно видео есть по ссылке.
Если у кого-то все еще остались трудности, то вот небольшой лайфхак: сперва начни произнесение с длительного звука |жжж| или |ZZZ| и затем, не прерывая его, отодвигай кончик языка назад к заднему скату альвеол, сделав проход для воздуха шире, чем для |ж|. Не допускай вибрирования языка. Вуаля!
Тренировка: произношение английской буквы r
Теперь попрактикуемся и произнесем несколько десятков слов с этим звуком:
run /rʌn/
rice /raɪs/
rat /ræt/
rag /ræɡ/
rake /reɪk/
red /red/
wrist /rɪst/
raisin /ˈreɪ.zən/
rabbit /ˈræb.ɪt/
ribbon /ˈrɪb.ən/
radio /ˈreɪ.di.əʊ/
rocket /ˈrɒk.ɪt/
ranch /rɑːntʃ/
rich /rɪtʃ/
race /reɪs/
ring /rɪŋ/
rain /reɪn/
rug /rʌɡ/
ran /ræn/
write /raɪt/
rip /rɪp/
recess /rɪˈses/
rock /rɒk/
read /riːd/
wrap /ræp/
carrot /ˈkær.ət/
zero /ˈzɪə.rəʊ/
Супер! Усложним задачу скороговорками.
Скороговорки: произношение звука |r| в английском языке
- Robert Rowley rolled a round roll around, a round roll Robert Rowley rolled around. If Robert Rowley rolled a round roll around, where is the round roll Robert Rowley rolled around?
- Rose Reed replants red roses, And the red roses ramp around a rail. If Rose Reed didn’t replant the red roses, Would the red roses ramp around the rail?
- Strawberries, raspberries and red-currents with real cream are really very refreshing.
- A right-handed fellow named Wright in writing “write” always wrote “right” where he meant to write right. If he’d written “write” right, Wright would not have wrought rot writing “rite”.
По традиции, мы завершим статью музыкальным примером. Я остановилась на песне “Run Run Run” группы Junge Junge, где нужный нам звук повторяется на протяжении всего первого куплета.
Оставайся с нами
Ну что, нам осталось разобрать 12 звуков. В следующий раз остановимся на звуках | n | и | ŋ |. Пока посмотри видео с нашего youtube-канала, из которого ты узнаешь полезное упражнение для хорошего произношения.
corp.lingualeo.com
R и Python — достойные соперники? / Издательский дом «Питер» corporate blog / Habr
Всем доброй пятницы, дорогие читатели!
В истории компьютерной редакции издательства «Питер» найдется немного столь успешных книг, как «Программируем на Python» Майкла Доусона и не больше таких противоречивых тем, как изумительный язык R, прочно закрепившийся в числе бестселлерных тем «Амазона». В настоящее время мы договариваемся с правообладателями о новой замечательной книге по Python, но в то же время хотели проверить общественное мнение о R — целесообразно ли издавать новые книги об этом элитарном языке для гуру большой статистики, либо Python легко его одолеет, не то что Аполлона?
Добро пожаловать под кат!
Языки Python и R спорят за звание «наилучшего» инструмента для работы с данными, и у обоих соперников есть свои достоинства и недостатки. Выбор того или иного языка зависит от конкретной ситуации, издержек на обучение, а также от того, какие еще распространенные инструменты требуются для решения задачи
Студенты часто интересуются, каким языком – R и/или Python лучше пользоваться при решении повседневных задач, связанных с анализом данных. Я обычно предлагаю интерактивные руководства по R, но уточняю, что в каждом конкретном случае выбор зависит от типа поставленной задачи, данные по которой требуется проанализировать.
Python и R — популярные языки программирования для работы со статистикой. В то время, как язык R разрабатывался с прицелом именно на потребности статистиков (вспомните только, какими мощными возможностями визуализации данных обладает R!), Python славен своим понятным синтаксисом.
В этой статье будут рассмотрены важнейшие отличия между языками R и Python, а также рассказано, какое место они оба занимают в мире изучения данных и статистики. Если вы предпочитаете инфографику, посмотрите разработку ”Data Science Wars: R vs Python”.
Знакомство с R
Росс Айхэка и Роберт Джентлмэн создали свободный язык R в 1995 году как свободную реализацию языка программирования S. Они стремились разработать язык, который обеспечивал бы более качественный и понятный подход к анализу данных, статистике и графическим моделям. На первых порах R использовался преимущественно в академической и научно-исследовательской среде, но сравнительно недавно стал проникать и в мир больших корпораций. Поэтому R — один из наиболее бурно развивающихся статистических языков, используемых в корпоративной практике.
Одно из основных достоинств R — огромное сообщество разработчиков, занимающихся поддержкой языка в почтовых рассылках, службе пользовательской документации и в очень активной группе на Stack Overflow. Также существует CRAN, гигантский репозиторий рекомендованных пакетов R, в разработке которых могут участвовать все желающие. Эти пакеты представляют собой коллекцию функций и данных R, они обеспечивают мгновенный доступ к новейшим приемам и функционалу, избавляя программиста от необходимости все изобретать самостоятельно.
Наконец, если вы – опытный разработчик, то вам, вероятно, не составит труда быстро освоить R. Начинающему программисту, возможно, придется туго, поскольку кривая обучения R очень крутая. К счастью, в настоящее время существует множество отличных учебных ресурсов по R.
Знакомство с Python
Язык Python был создан Гвидо ван Россумом в 1991 году. В этом языке делается акцент на производительности и удобочитаемости кода. Среди программистов, желающих погрузиться в анализ данных и пользоваться статистическими приемами, немало активных пользователей Python, применяющих этот язык именно в статистической сфере. Чем активнее вы углубляетесь в среду технарей, тем больше вам, по всей вероятности, будет нравиться Python. Этот гибкий язык отлично подходит для всего новаторского. Учитывая его простоту и удобочитаемость, кривая обучения для этого языка сравнительно пологая.
Как и в R, в Python есть пакеты. PyPi — это список пакетов Python, в нем содержатся библиотеки, дополнять которые может любой пользователь. Как и R, Python обладает большим сообществом разработчиков, но оно несколько неоднородное, поскольку Python — универсальный язык. Тем не менее, именно наука о данных стремительно занимает все более внушительные позиции во вселенной Python: ожидания растут, одно за другим появляются новые приложения по работе с данными.
R и Python: Общие показатели
В Сети можно встретить массу количественных сравнений распространенности и популярности R и Python. Хотя такие показатели и позволяют уверенно сориентироваться в том, как эти два языка развиваются в общем контексте информатики, сравнить их напрямую нелегко. Основная причина заключается в том, что сфера использования R ограничена наукой о данных. Python, в свою очередь, будучи универсальным языком, широко применятся во многих сферах, например, в веб-разработке. Поэтому рейтинги зачастую искажаются в пользу Python, тогда как зарплаты оказываются существенно выше у специалистов по R.
Когда и как использовать R?
R обычно применяется в тех случаях, когда для анализа данных требуются выделенные вычислительные мощности или отдельные сервера. R отлично подходит для исследовательской работы, удобен практически при любом варианте анализа данных, поскольку в языке R существует масса пакетов и готовые тесты, обеспечивающие нужный инструментарий для быстрого старта. R даже может быть элементом решения в области больших данных.
Приступая к работе с R, целесообразно для начала установить замечательную IDE RStudio. Затем рекомендую ознакомиться со следующими популярными пакетами:
- dplyr, plyr и data.table, упрощающие манипуляции с пакетами,
- stringr для работы со строками,
- zoo для работы с регулярными и иррегулярными временными последовательностями,
- ggvis, lattice и ggplot2 для визуализации данных и
- caret для машинного обучения
Когда и как использовать Python?
Python пригодится в случаях, когда задачи, связанные с анализом данных, вплетаются в работу веб-приложений, или если статистический код требуется инкорпорировать в рабочую базу данных. Python, будучи полнофункциональным языком программирования, отлично подходит для реализации алгоритмов с их последующим практическим использованием. Еще недавно пакеты для анализа данных на Python находились в зачаточном состоянии, что представляло определенную проблему, но в последние годы ситуация значительно улучшилась. Обязательно установите NumPy /SciPy (научные вычисления) и pandas (манипуляции с данными), чтобы приспособить Python для анализа данных. Кроме того, обратите внимание на библиотеку matplotlib для создания графики и scikit-learn для машинного обучения.
В отличие от R, для Python не существует ярко выраженной “выигрышной” IDE. Желательно ознакомиться со Spyder, IPython Notebook и Rodeo и выбрать ту, которая лучше всего вам подходит.
R и Python: доли в сегменте науки о данных
Если рассмотреть недавние опросы, связанные с популярностью различных языков, используемых при анализе данных, то зачастую R выглядит явным лидером. Если конкретно сравнить позиции Python и R в этом сообществе, то вырисовывается схожая картина.
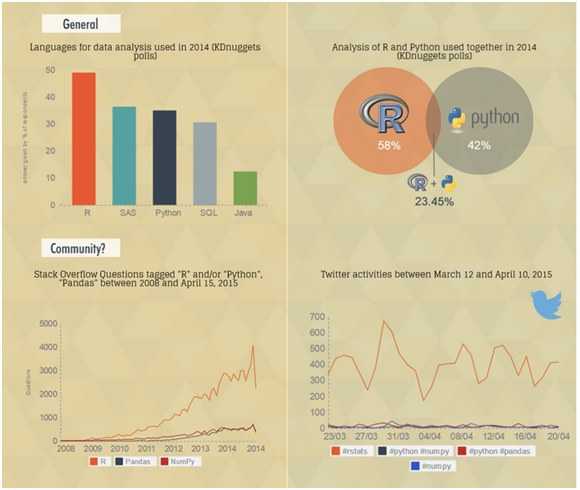
Несмотря на вышеприведенную инфографику, есть основания полагать, что все больше специалистов переходят с R на Python. Более того, растет доля тех программистов, которые владеют обоими языками и по мере необходимости используют то один, то другой. Именно такую тактику я рекомендую моим студентам.
Если вы планируете делать карьеру в науке о данных, то вам потребуется освоить оба языка. Тенденции на рынке труда свидетельствуют растущий спрос на оба навыка, а зарплаты в этом сегменте существенно выше средних.
R: Плюсы и минусы
Плюс: Картинка бывает информативнее тысячи слов
Если данные визуализировать, то они зачастую становятся выразительнее и понятнее, чем голые числа. Язык R просто создан для визуализаций. Обязательно ознакомьтесь с пакетами для визуализации ggplot2, ggvis, googleVis и rCharts.
Плюс: экосистема R
R обладает богатой экосистемой ультрасовременных пакетов и располагает активным сообществом. Пакеты доступны в репозиториях CRAN, BioConductor и Github. Все пакеты R можно просмотреть по адресу Rdocumentation.
Плюс: R – лингва-франка науки о данных
Язык R разрабатывался статистиками для статистиков. Они могут обмениваться идеями и концепциями при помощи кода и пакетов R, кроме того, для погружения в эту тему им не обязательно обладать базовыми знаниями по информатике. Кроме того, язык все шире распространяется в неакадемической среде.
Плюс/минус: R — медленный язык
R создавался, чтобы облегчить работу статистикам, а не вашему компьютеру. R может казаться медленным из-за некачественно написанного кода, однако существует множество пакетов, повышающих производительность R: pqR, renjin и FastR, Riposte и многие другие.
Минус: R сложен в изучении
Кривая обучения языку R нетривиальна, особенно если вы беретесь за статистический анализ, опираясь на графический интерфейс. Даже поиск пакетов может занять много времени, если вам это в новинку.
Python: плюсы и минусы
Плюс: IPython Notebook
Инструмент IPython Notebook облегчает работу с Python и данными. Не составит труда использовать такой блокнот вместе с коллегами, причем им даже не придется ничего устанавливать. В таком случае резко снижаются издержки, связанные с организацией кода, файлами вывода и заметок. Вы сможете уделить больше времени полезной работе.
Плюс: универсальный язык
Python – универсальный язык, простой и интуитивно-понятный. Кривая обучения у него сравнительно пологая, на этом языке вы сможете быстрее писать программы. Короче говоря, на код тратится мало времени, а на разные интересности – много!
Более того, в Python встроен фреймворк для тестирования, входной барьер у которого очень низок. Фреймворк обеспечивает хорошее тестовое покрытие. Таким образом, ваш код будет надежен и удобен для многократного использования.
Плюс: многоцелевой язык
Python объединяет людей, начинавших карьеру в разных сферах. Поскольку это простой и распространенный язык, не только понятный многим программистам, но и легкий для специалистов по статистике, на нем можно написать такой инструмент, в котором будут интегрированы все этапы вашего рабочего процесса.
Плюс/Минус: Визуализации
Возможность визуализации – важный критерий при подборе софта для анализа данных. Хотя в Python и есть приятные библиотеки для визуализации, например, Seaborn, Bokeh и Pygal, выбор может быть излишне велик. Более того, по сравнению с R, визуализация на Python устроена гораздо сложнее, а ее результаты порой не слишком наглядны.
Минус: Python играет на чужом поле
Python — конкурент R. Но в нем нет альтернатив для сотен важнейших пакетов R. Пусть Python и успешно догоняет, неясно, будут ли люди ради него отказываться от R?
А победителя…
Определяете вы! Как специалист по данным, вы должны сами подобрать себе язык для работы. Постарайтесь ответить на следующие вопросы:
- Какие проблемы вам требуется решать?
- Во что вам обойдется изучение нового языка?
- Какие инструменты активно используются в вашей профессиональной сфере?
- Какие альтернативы существуют для этих инструментов?
Удачи!
habr.com
Архивы Обучение и тренировки — R-dance
Как реализовать художественный замысел танца
Июнь 20, 2019 Автор:admin Краткосрочные и долгосрочные цели, которые ставит перед собой тренер, должны найти отклик у танцора. Он должен быть готов и в состоянии реализовать замысел танца. Чем больше совпадают цели танцовщика и хореографа, тем более лёгким будет решение танцевать. Позиция танцовщика положительная, работа ему доставляет радость, — вплоть до восторга.
Краткосрочные и долгосрочные цели, которые ставит перед собой тренер, должны найти отклик у танцора. Он должен быть готов и в состоянии реализовать замысел танца. Чем больше совпадают цели танцовщика и хореографа, тем более лёгким будет решение танцевать. Позиция танцовщика положительная, работа ему доставляет радость, — вплоть до восторга.
[Продолжение…]
Тело танцора – Джозеф Хавилер
Май 24, 2018 Автор:adminДля танцора его тело является инструментом самовыражения. Поэтому для дальнейшего совершенствования необходимы знания о конституции, типах телосложения, анатомическом строении и функциональности отдельных частей тела. При таком подходе танцор сможет защитить своё тело и надолго сохранить здоровье организма в целом. [Продолжение…]
Энергетика в танце
Май 8, 2018 Автор:adminТанцевальная пара – это единый организм, подвластный общим законам движений, действий и жестов. Танцоры соединяются на общей оси баланса, а их пластика становится изометрической, то есть взаимосвязанной и подчиненной одной общей плоскости. Отчетливо ось баланса прослеживается в латиноамериканской программе, для которой свойственны точки ведения и подчинения ведению. [Продолжение…]
Танцевальные сборы 2019
Май 2, 2018 Автор:admin
А Бонифаций думал: «Какая все-таки замечательная вещь, каникулы!».
Лето – это не сезон между весной и осенью, а пространное место, где неизвестно сколько сейчас времени и какой сегодня день недели. Пребывание в таком пространстве полезно для оздоровления и развития по всем направлениям. Лето предоставляет условия для общения и творческой самореализации в игре, познании, искусстве и спорте. [Продолжение…]
ОФП в спортивных бальных танцах
Март 24, 2018 Автор:adminТанцору приходится прилагать много усилий для работы над танцем, но не следует забывать про общую физическую подготовку. Хорошая физическая выносливость играет не последнюю роль в подготовке спортсменов, сказывается благоприятно, в целом, на качестве жизни. [Продолжение…]
r-dance.club